

Esta es nuestra segunda parte del especial «De 0 a 100 en Inteligencia Artificial«.
En nuestro primer artículo, abordamos la introducción a la Inteligencia Artificial, conocimos sus fundamentos y cómo ha revolucionado el mundo de la informática. Pero hoy vamos a bajar al subsuelo del código y descubrir una de sus ramas más fascinantes: el Procesamiento del Lenguaje Natural (NLP).
Si alguna vez te has preguntado qué es el procesamiento del lenguaje natural, cómo un chatbot parece «entenderte» o por qué tu asistente virtual a veces responde estupideces, bienvenido. Nos sumergiremos en los engranajes de esta tecnología, desde su historia hasta los modelos más avanzados.
Ponte cómodo, porque esto va a ser una auténtica disección geek del tema.
¿Qué es el Procesamiento del Lenguaje Natural?
Para responder a esta pregunta, hagamos un ejercicio mental. Imagina que tienes que programar un intérprete de lenguaje humano desde cero. En teoría, parece fácil: solo tendrías que decirle a la máquina que «entienda» palabras y les asigne significados. Pero aquí viene el problema:
- La ambigüedad: no es lo mismo decir «Banco de madera» que «Banco de inversión«.
- El contexto: «Está frío aquí» puede significar que hace frío, que la comida no está caliente o que el ambiente es distante.
- El sarcasmo e ironía: «Vaya, qué gran idea» puede ser tanto literal como completamente sarcástico.
Aquí es donde entra el Procesamiento del Lenguaje Natural (NLP), que no es más que el área de la Inteligencia Artificial que permite a las máquinas interpretar, generar y procesar texto y voz en lenguaje humano.
En términos computacionales, el NLP es un conjunto de algoritmos, modelos estadísticos y redes neuronales diseñadas para transformar texto en datos estructurados que una máquina pueda analizar. Es la pieza clave detrás de herramientas como asistentes virtuales, traductores automáticos, motores de búsqueda y chatbots.
Pero esta tecnología no nació de la nada. Ha recorrido un camino largo y lleno de desafíos.
Historia y evolución del Procesamiento del Lenguaje Natural
En términos simples, el NPL es el puente entre la informática y la lingüística, permitiendo que los programas interpreten, analicen y generen lenguaje humano.
Las primeras reglas: Lenguaje enlatado (1950-1980)
Las primeras aproximaciones al NLP eran como los lenguajes de programación de bajo nivel: rígidas y basadas en reglas. Los programadores diseñaban sistemas con conjuntos de reglas sintácticas y léxicas que determinaban cómo interpretar frases.
- Ejemplo clásico: ELIZA (1966), un programa de chatbot basado en reglas que simulaba una conversación con un terapeuta. No entendía nada realmente, solo aplicaba patrones predefinidos.
- Problema: esto no escalaba. El lenguaje humano es ambiguo, contextual y evolutivo. Codificar manualmente todas las posibles variaciones era como escribir un kernel desde cero sin librerías.
Métodos estadísticos: Machine Learning entra en escena (1990-2000)
Con el auge del machine learning, el NLP dio un salto. En lugar de depender de reglas escritas por humanos, los modelos comenzaron a aprender patrones a partir de datos masivos.
- Ejemplo clásico: los primeros modelos de traducción automática, como los de Google en sus inicios, usaban modelos basados en probabilidad. Daban mejores resultados, pero eran un poco como una base de datos SQL; consultaban registros previos y hacían cálculos, sin entender realmente lo que decían.
Deep Learning y la revolución actual: Modelos basados en Transformers (2018-Actualidad)
Aquí es donde las redes neuronales cambiaron todo. En 2018, Google presentó BERT, un modelo que entendía el contexto de las palabras en ambas direcciones, algo revolucionario para el análisis de texto. Poco después, OpenAI lanzó GPT-3, un modelo de procesamiento del lenguaje natural capaz de generar textos completos con coherencia asombrosa.
Hoy en día, tenemos Gemini de Google, Claude de Anthropic y GPT-4.5, cada uno más avanzado, más preciso y más aterradoramente bueno en la generación de texto.
¿Qué los hace tan especiales? La clave está en su arquitectura Transformer, que permite procesar información en paralelo en lugar de hacerlo secuencialmente. Esto es como comparar un procesador mononúcleo con uno multinúcleo; la diferencia de velocidad y eficiencia es brutal.
Fundamentos del Procesamiento del Lenguaje Natural
Para entender cómo entrenar un modelo de procesamiento del lenguaje natural, hay que desglosar sus componentes clave. Es como si quisieras escribir tu propio compilador: primero necesitas conocer bien la estructura del código fuente.
Aquí hay que mencionar varias técnicas fundamentales:
1. Tokenización: Partiendo el texto en pedazos útiles
En informática, antes de que un compilador procese código, lo divide en tokens. Lo mismo hace el NLP con el lenguaje humano:
Ejemplo en Python usando la librería nltk:

Salida: [‘Hoy’, ‘el’, ‘clima’, ‘está’, ‘increíble’, ‘.’]
Sin tokenización, un modelo de NLP sería incapaz de entender estructuras lingüísticas, de la misma forma que un compilador no podría analizar código sin dividirlo en palabras clave, operadores y estructuras sintácticas.
2. Análisis sintáctico y semántico: De palabras a significado
El siguiente paso es identificar cómo se relacionan las palabras en una oración. No es lo mismo decir:
- «Juan vio a María con los binoculares.»
«Juan vio a María, quien tenía los binoculares.»
Aquí entra el parsing sintáctico, que analiza la estructura gramatical de las oraciones.
Ejemplo en Python con spaCy:
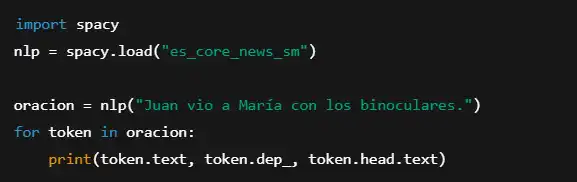
Salida:
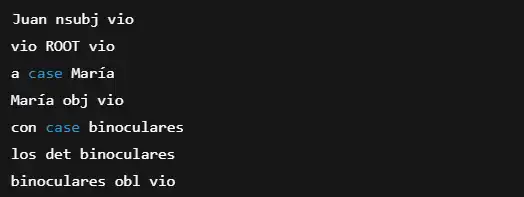
El modelo nos dice que «binoculares» está relacionado con «vio», lo que sugiere que Juan tenía los binoculares y no María. Este tipo de análisis es fundamental en aplicaciones como asistentes de voz, motores de búsqueda y traducción automática.
3. Reconocimiento de entidades nombradas (NER): Distinguir lo importante
A veces, lo que nos interesa en un texto no es toda la información, sino ciertos elementos clave: nombres propios, fechas, lugares.
Ejemplo con spaCy:
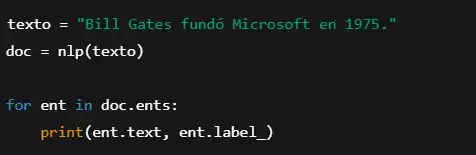
Salida esperada:
- Bill Gates PERSON
- Microsoft ORG
- 1975 DATE.
Esto es oro puro para motores de búsqueda, análisis de noticias y herramientas de análisis de datos.
4. Análisis de sentimientos: Detección de emociones en texto
Los algoritmos de NLP pueden determinar si un comentario es positivo, negativo o neutro. Esto es realmente interesante y valioso para empresas que analizan opiniones en redes sociales.
- Ejemplo real: modelos de análisis de sentimientos en e-commerce, donde el NLP ayuda a detectar qué productos generan más quejas.
Modelos de Lenguaje en Procesamiento del Lenguaje Natural
Antes de construir un modelo propio, hay que entender qué opciones existen y cómo funcionan.
Hoy en día, los modelos de NLP se basan principalmente en redes neuronales profundas y han evolucionado hasta convertirse en verdaderas bestias del análisis de texto. Aquí están los más importantes.
1. GPT (Generative Pre-trained Transformer)
GPT, desarrollado por OpenAI, es el ejemplo más famoso de modelo de procesamiento del lenguaje natural basado en Transformers.
Características principales:
- Es un modelo generativo: se basa en la predicción de la siguiente palabra dentro de una secuencia, sin necesidad de que el texto esté completamente estructurado.
- Es autoregresivo: aprende a generar contenido palabra por palabra basándose en el contexto previo.
- Aprende con entrenamiento no supervisado: se entrena con grandes volúmenes de texto sin etiquetas explícitas.
Ejemplo de uso en código:
Utilizando la API de OpenAI, podemos generar texto con GPT-4 en Python:
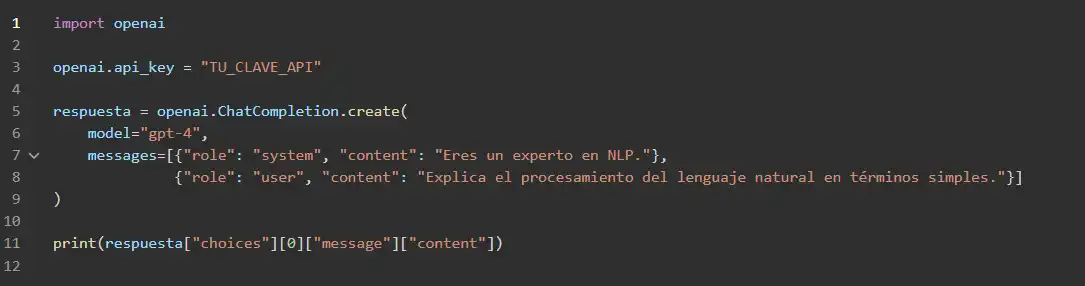
Este modelo es excelente para tareas como generación de texto, asistencia conversacional, redacción automática y programación en lenguaje natural.
2. BERT (Bidirectional Encoder Representations from Transformers)
BERT, desarrollado por Google, es un modelo diseñado para comprender el significado de una oración analizando el contexto en ambas direcciones.
Diferencias con GPT:
- BERT es un modelo bidireccional: eExamina el contexto a la izquierda y derecha de una palabra en una oración.
- Es un modelo de comprensión, no generativo: se usa en tareas como búsqueda semántica y análisis de texto, pero no para generar contenido libre.
- Requiere fine-tuning: BERT necesita ajustes específicos para cada tarea (como clasificación de texto o respuesta a preguntas).
Ejemplo de uso con transformers de Hugging Face:
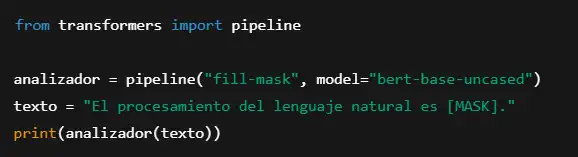
Salida esperada: [‘importante’, ‘fundamental’, ‘crucial’, ‘avanzado’]
BERT es la columna vertebral de los motores de búsqueda modernos. Google lo usa para interpretar mejor las consultas y ofrecer resultados más relevantes.
3. Claude (Anthropic) y su enfoque en «IA Constitucional»
Claude, desarrollado por Anthropic, es un modelo basado en GPT pero con una diferencia clave: está diseñado para generar respuestas alineadas con principios éticos.
En lugar de entrenarse solo con feedback humano (como GPT), Claude usa un conjunto de reglas explícitas que guían su comportamiento.
Ejemplo de aplicación: empresas que buscan chatbots más seguros y alineados con valores específicos.
4. Gemini (Google DeepMind): La nueva generación multimodal
Gemini es el primer modelo de Google construido desde cero para ser multimodal, lo que significa que no solo procesa texto, sino también imágenes, audio y video.
Diferencias con otros modelos:
- Nativo en múltiples modalidades: puede analizar texto junto con imágenes o videos sin necesidad de integrar modelos externos
- Capacidad de razonamiento mejorada: es capaz de realizar tareas complejas como planificación y resolución de problemas
- Optimizado para eficiencia: puede ejecutarse en dispositivos móviles con variantes más ligeras como Gemini Nano.
Estos modelos están marcando la pauta en la evolución del procesamiento del lenguaje natural para principiantes y expertos, ya que ofrecen capacidades sin precedentes en comprensión y generación de lenguaje.
Cómo entrenar un modelo de Procesamiento del Lenguaje Natural
Ahora que hemos visto los modelos existentes, llega la parte que todo programador quiere saber: cómo entrenar un modelo de procesamiento del lenguaje natural desde cero.
1. Recolectar y preprocesar datos
Antes de entrenar cualquier modelo, necesitas un dataset de calidad.
Ejemplo de dataset:
- Corpus de Wikipedia: perfecto para entrenar modelos de comprensión de lenguaje
- Tweets etiquetados para análisis de sentimientos
- Datos de atención al cliente para entrenamiento de chatbots.
Ejemplo en Python para limpiar datos con pandas:
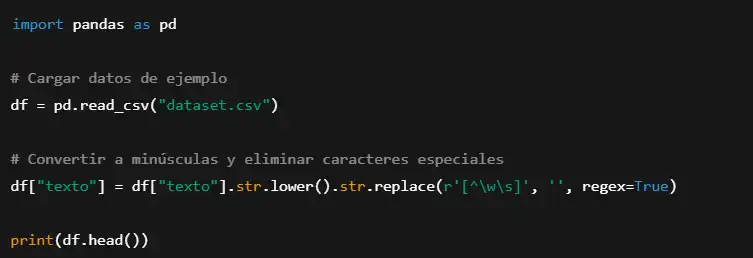
2. Entrenamiento de un Modelo con Transformers
Para entrenar un modelo de NLP desde cero, usamos transformers y datasets de Hugging Face.
Ejemplo de fine-tuning de BERT para clasificación de texto:
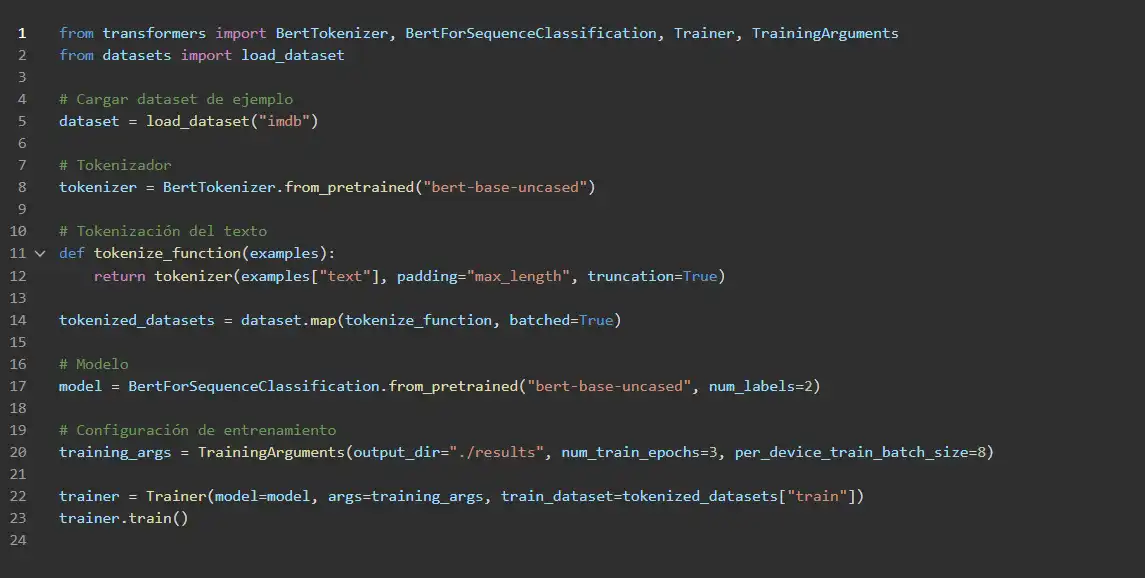
Este código entrena un modelo de clasificación de textos para análisis de sentimientos.
Aplicaciones reales del Procesamiento del Lenguaje Natural
Hoy en día, como somos conscientes la mayoría, vemos que el procesamiento del lenguaje natural está presente en prácticamente todas las interacciones digitales. Cada vez que hablas con un asistente de voz, traduces un texto o realizas una búsqueda en Google, estás utilizando NLP.
Vamos a analizar los casos más representativos y cómo funcionan en términos técnicos.
1. Asistentes Virtuales: NLP en la voz del futuro
Los asistentes de voz como Siri, Alexa y Google Assistant (ahora Gemini) han sido pioneros en el uso del NLP para la comprensión del lenguaje hablado.
¿Cómo funcionan?
- Conversión de voz a texto (ASR – Automatic Speech Recognition): convierte el audio en texto con modelos de redes neuronales como Whisper de OpenAI
- Procesamiento del texto con NLP: el sistema analiza la oración y detecta la intención del usuario
- Ejecución de la acción: una vez entendida la intención, el sistema ejecuta una acción (como reproducir música o dar una respuesta)
- Conversión de texto a voz (TTS – Text-to-Speech): se genera una respuesta hablada para el usuario.
Ejemplo en código con SpeechRecognition en Python:
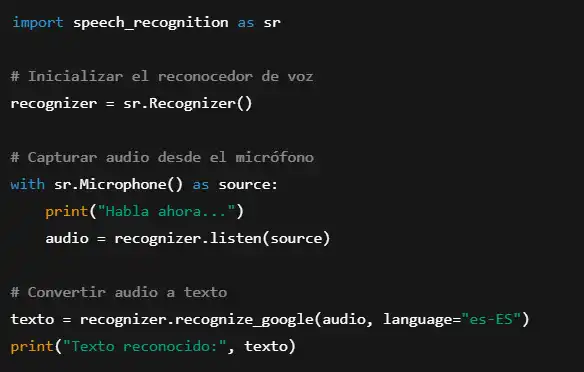
Este script permite capturar voz y convertirla en texto con la API de Google.
2. Motores de Búsqueda: El corazón del NLP en Internet
Hemos visto como Google a través de los años ha logrado mejorar drásticamente sus algoritmos de búsqueda, y todo gracias al NLP. Antes, los motores de búsqueda coincidían palabras clave; ahora entienden el significado de las consultas.
¿Cómo funciona la búsqueda semántica?
- Tokenización y análisis sintáctico de la consulta del usuario.
- Transformación en vectores de significado con modelos como BERT.
- Búsqueda de documentos semánticamente relacionados en el índice de Google.
- Ordenación de los resultados según la relevancia del contenido.
Ejemplo de búsqueda semántica con sentence-transformers:
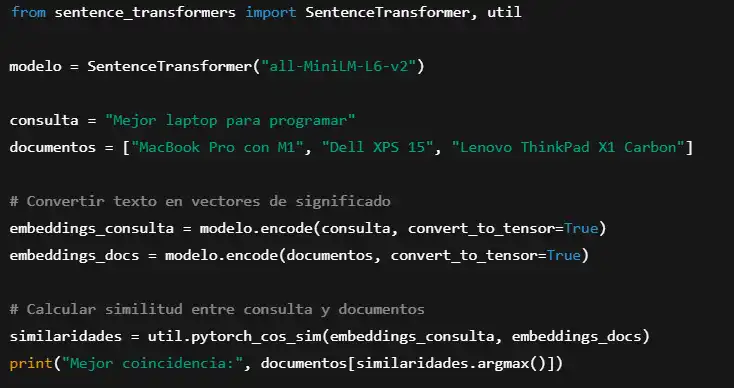
Este código simula cómo un motor de búsqueda seleccionaría el mejor resultado basándose en significado en lugar de palabras clave exactas.
3. Traducción automática: De Google Translate a modelos propios
Los sistemas de traducción automática han evolucionado enormemente gracias a los Transformers. Antes, los modelos basados en reglas y estadística producían traducciones robóticas y literales. Ahora, modelos como MarianMT, NLLB-200 y Google Translate pueden generar traducciones más fluidas y naturales.
Ejemplo con transformers de Hugging Face:
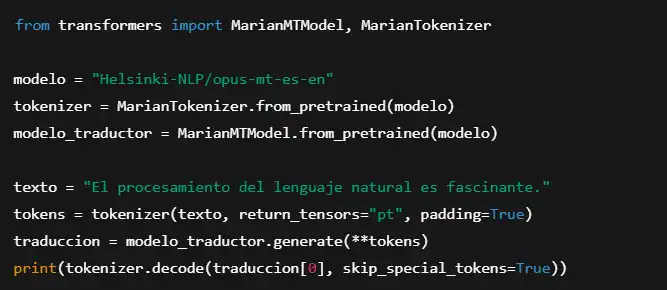
Este código traduce texto de español a inglés utilizando un modelo basado en Transformers.
Implementación del NLP en Producción
Construir un modelo en Jupyter Notebook es una cosa, pero ponerlo en producción es un desafío completamente distinto.
Desplegando un Modelo de NLP con FastAPI
Para integrar un modelo de NLP en una API lista para producción, podemos usar FastAPI.
Ejemplo de una API REST para analizar sentimientos con BERT:
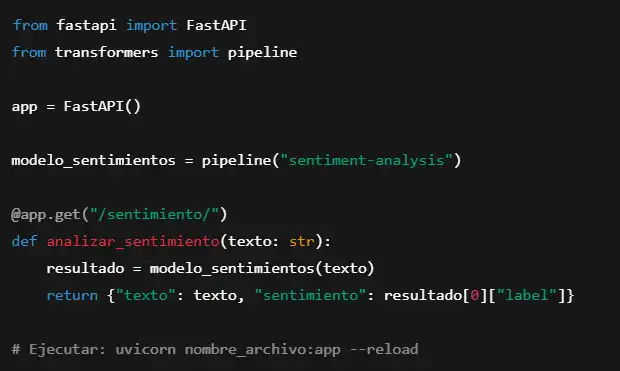
Esto permite enviar peticiones HTTP y obtener análisis de sentimiento en tiempo real.
Desafíos y futuro del NLP
A pesar de los avances, el procesamiento del lenguaje natural sigue enfrentando desafíos significativos. Vamos a ver algunos de los que más preocupan:
1. Sesgo en los modelos de lenguaje
Los modelos de NLP aprenden de grandes volúmenes de datos de Internet, lo que significa que pueden reflejar prejuicios y sesgos sociales.
- Ejemplo: si entrenamos un modelo en datos no filtrados, podría generar respuestas discriminatorias o inexactas.
- Solución: técnicas como el ajuste con retroalimentación humana (RLHF) o la IA Constitucional de Claude, que entrenan los modelos para dar respuestas más éticas.
2. Privacidad y seguridad de los datos
Uno de los mayores desafíos del NLP es manejar información sensible sin comprometer la privacidad del usuario.
- Ejemplo: un chatbot en una empresa médica no debería almacenar información privada de los pacientes.
- Solución:
- Inferencia en el dispositivo (como Gemini Nano).
- Técnicas de anonimización de datos en NLP.
3. Modelos Multimodales y Agentes Inteligentes
El futuro del NLP no solo está en el texto, sino en la combinación con imágenes, audio y video. Gemini 2.0 ya ha mostrado capacidad de manejar videos e interpretar contenido visual en tiempo real. Lo mismo con ChatGPT, donde puedes compartir la cámara y conversar sobre cosas que presentes en la cámara.
Esto sin lugar a dudas abre la puerta a asistentes de IA capaces de comprender no solo lo que decimos, sino también lo que vemos y oímos. Cosa que, en menos de lo que creemos estará presente en cada rincón de la sociedad.
Hemos recorrido el NLP desde sus inicios hasta su implementación en sistemas reales. Desde ELIZA hasta GPT-4, desde simples reglas gramaticales hasta modelos multimodales avanzados.
Si algo ha quedado claro, es que el procesamiento del lenguaje natural ha cambiado la forma en que interactuamos con la tecnología.
Lo que antes era solo un conjunto de reglas sintácticas es hoy una inteligencia capaz de conversar, comprender y generar texto con una fluidez sin precedentes.
Pero esto es solo el principio. Con modelos cada vez más avanzados y técnicas de entrenamiento más refinadas, el NLP seguirá evolucionando hasta convertirse en una pieza fundamental de la informática del futuro.
")






